Voice to 3D
I built a workflow with a voice interface to create and modify AI slop 3D models and then have them printed. This started after a conversation in June with Mike K about UX models for a layperson (user) using AI to create something incredibly complex like a car. This thought exercise was speculating on something that seems very far off but with a goal of starting to chip away at how someone might control the new type of systems AI models allow. My curiousity was peeked and jumped in on making the simplist version I could think of.
Approach
I saw value in a quick feedback loop to iterate and correct a system as it learns the requirements without a heavy upfront input step. I broke the problem up into several bigger chunks to focus on: user input, determining the intent, and outputting the synthesis.
Input
From my work with voice interfaces on Alexa, I like voice as a fast input for open ended commands. It's much faster, in most cases, to transfer an idea from user to the machine than text input. A pre-LLM challenge of text input was that people are usually thinking as their speaking and need to change their thought after they've already started speaking. LLMs are very forgiving for improper grammar, incomplete commands, missed words, and even redirecting mid-command at figuring out the broader intention of the user input. An iterative process that I already planned would also allow some failure because the user would have an opportunity to correct it.
Intent Determination
I'd been wanting to experiement with the fine-tuning APIs of the major AI models. I prepared a dataset of command for 'create', 'modify', 'commit', and 'not-relevant', about 30 of each.
{
"messages": [
{
"role": "system",
"content": "You are an intent detection system. Classify freeform user inputs into one of four categories: create, modify, accept, or irrelevant. Extract the subject if present. Output only JSON in the format: {\"action\":\"<action>\", \"subject\":\"<subject>\"}.\n\nExamples:\n\n- Create:\n - \"create a spoon\"\n - {\"action\":\"create\", \"subject\":\"spoon\"}\n - \"write a passage about the weather\"\n - {\"action\":\"create\", \"subject\":\"passage about the weather\"}\n\n- Modify:\n - \"make it taller\"\n - {\"action\":\"modify\", \"subject\":\"taller\"}\n - \"add some flair\"\n - {\"action\":\"modify\", \"subject\":\"some flair\"}\n\n- Accept:\n - \"that looks good\"\n - {\"action\":\"accept\", \"subject\":\"continue\"}\n - \"confirm\"\n - {\"action\":\"accept\", \"subject\":\"confirm\"}\n\n- Irrelevant:\n - \"what's the weather\"\n - {\"action\":\"irrelevant\", \"subject\":\"\"}\n - \"tell me a joke\"\n - {\"action\":\"irrelevant\", \"subject\":\"\"}"
},
{
"role": "user",
"content": "make the wheels bigger"
},
{
"role": "assistant",
"content": "{\"action\":\"modify\", \"subject\":\"wheels bigger\"}"
}
]
}
Using a basic tutorial-level of complexity, I was getting results that could take a plain English command and output a JSON object with the 'action' and 'content'. There are limits in the narrowness of what it does but that is minor relative to the benefit of making sense of unstructured input for a user input.
Generation
For output, I experimented with a multi-step process I had used in the previous experiment where I text is convered to an image and then a 3D model generated from there. Image models, so far, are much more widely used and handle nuances better than the 3D models. This approach works fine for generating AI slop 3D models. One pain point is I was trying to run models on my own rented GPU. This seemed simpler than using multiple APIs for each step but ends up being a pain to start up the server and ensure it's configuration is up to date. A choice I thought would be faster and give me more control was unnecessary friction and I'll avoid in the future.



Commit
After displaying the generated model, the user can send it to the printer. PrusaSlicer has a CLI interface that allows for slicing and generating GCODE. Then sending the output to the printer using the local LAN API for my Prusa printer. Models are automatically scaled to a size that will print in under 30 minutes. The tray needs to be cleared between prints. [prints]
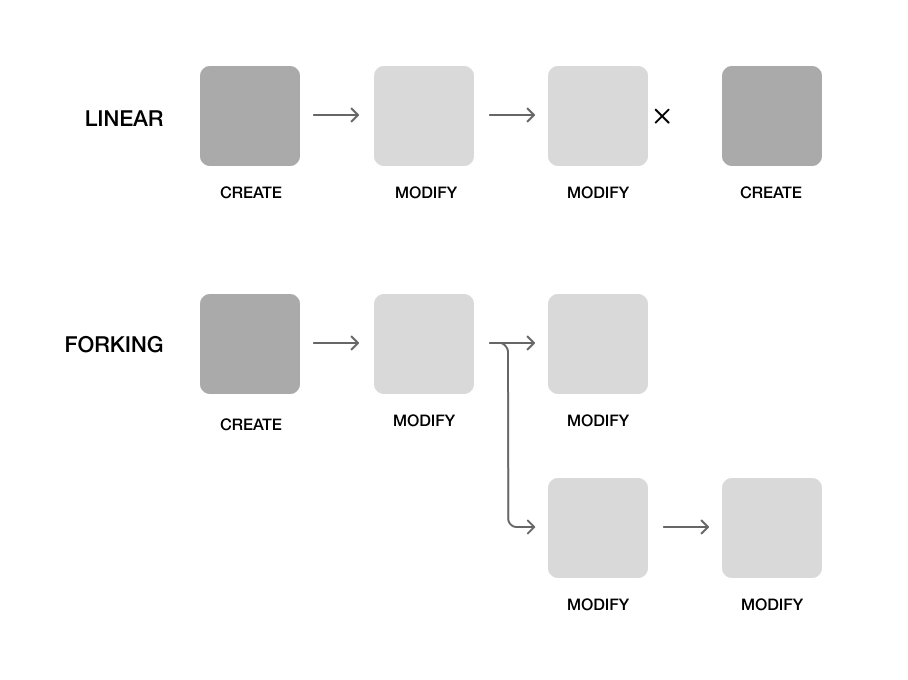
Reflection
The chose the simple what you see is where you are approach with no undo - there's only keep going or restart. This works for an initial demonstration with a system but doesn't allow for low-risk experimentation where someone can try something and then throw it away without losing their previous state. A forked approach may be better where you can take any creation and fork the creation path for new experiements.